A serverless pipeline that processes documents in parallel and generates vector embeddings for similarity search using AWS Step Functions, Lambda, and Amazon Bedrock
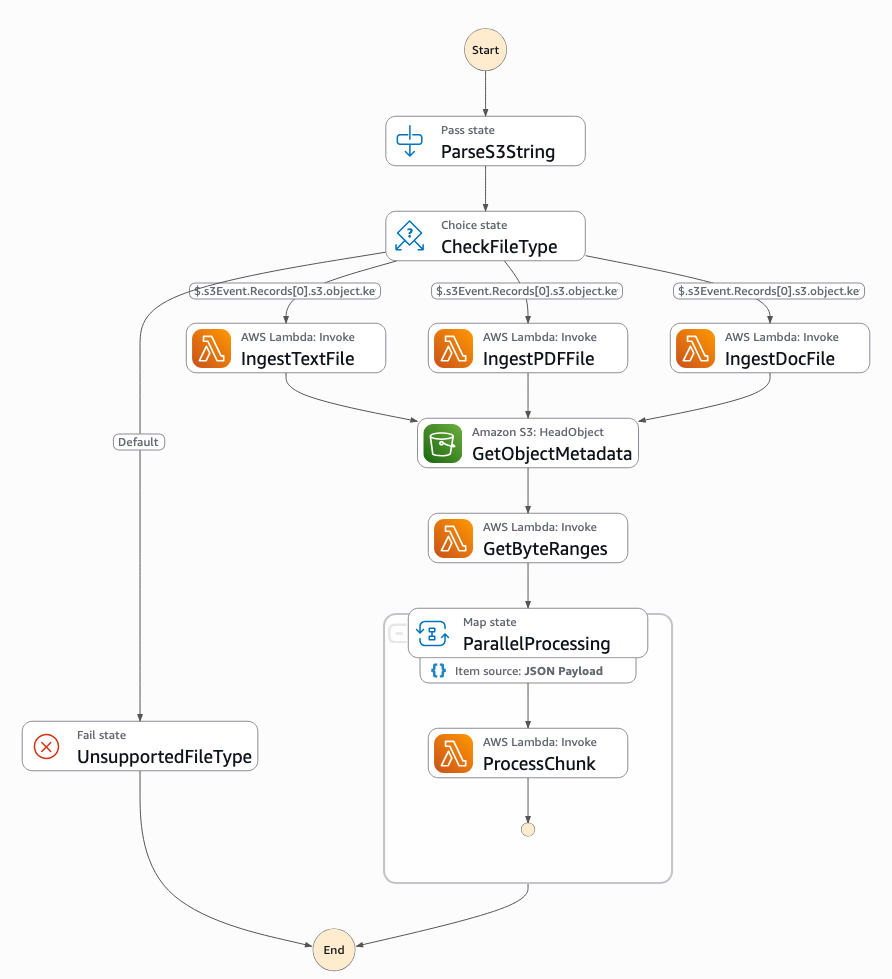
This sample project demonstrates how to build a production-ready document vectorization pipeline using AWS Step Functions to orchestrate parallel processing of documents. The pipeline intelligently handles different document formats and processes them in parallel chunks for optimal performance.
The state machine routes text, PDF, and Word documents to specialized Lambda functions for content extraction, then leverages parallel processing to generate vector embeddings using Amazon Bedrock's Titan models. All vectors are stored in PostgreSQL with pgvector extension for efficient similarity search.
Key features include automatic document type detection, parallel chunk processing, serverless scaling, and comprehensive error handling - making it suitable for high-throughput production workloads.
< Back to all workflows
Clone repo
git clone https://github.com/solaws/step-functions-workflows-collection/tree/main/parallelized-embedding-pipelinecd step-functions-workflows-collection/parallelized-embedding-pipeline
Deploy
Deploy the complete pipeline with database initialization: <code>./deploy-with-db-init.sh --region us-east-1</code>Or deploy infrastructure only: <code>sam build && sam deploy --guided</code>Then initialize the database: <code>./deploy-db-init.sh --region us-east-1</code>
Testing
See the GitHub repo for detailed testing instructions.
Cleanup
Delete the stack:
aws cloudformation delete-stack --stack-name vectorization-pipeline --region [YOUR-REGION]Or use SAM:
sam deleteAdditional resources
Created by:
