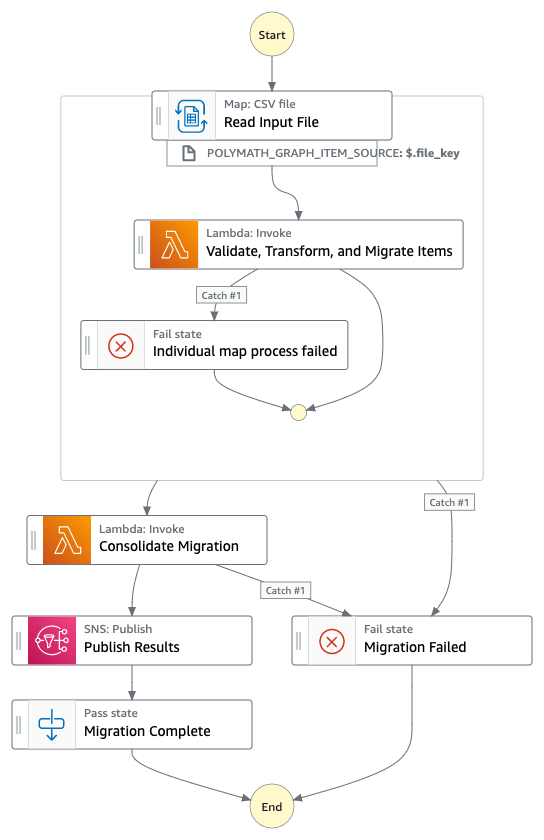
Streamlines large-scale DynamoDB migrations with parallel processing using the dynamic map state.
This workflow uses the distributed map state to achieve high concurrency when ingesting CSV files at scale. It then transforms and persists data to Amazon DynamoDB
< Back to all workflows
Clone repo
git clone https://github.com/aws-samples/step-functions-workflows-collection/tree/main/migrate-csv-to-ddb-distributed-map-main/cd step-functions-workflows-collection/migrate-csv-to-ddb-distributed-map-main
Deploy
1. Bootstrap CDK, if needed: cdk bootstrap aws://{your-aws-account-number}/{your-aws-region}2. Deploy the stack:cdk deploy
Testing
See the GitHub repo for detailed testing instructions.
Cleanup
cdk destroyCreated by:

