Wait for an asynchronous Job to finish before moving onto the next state
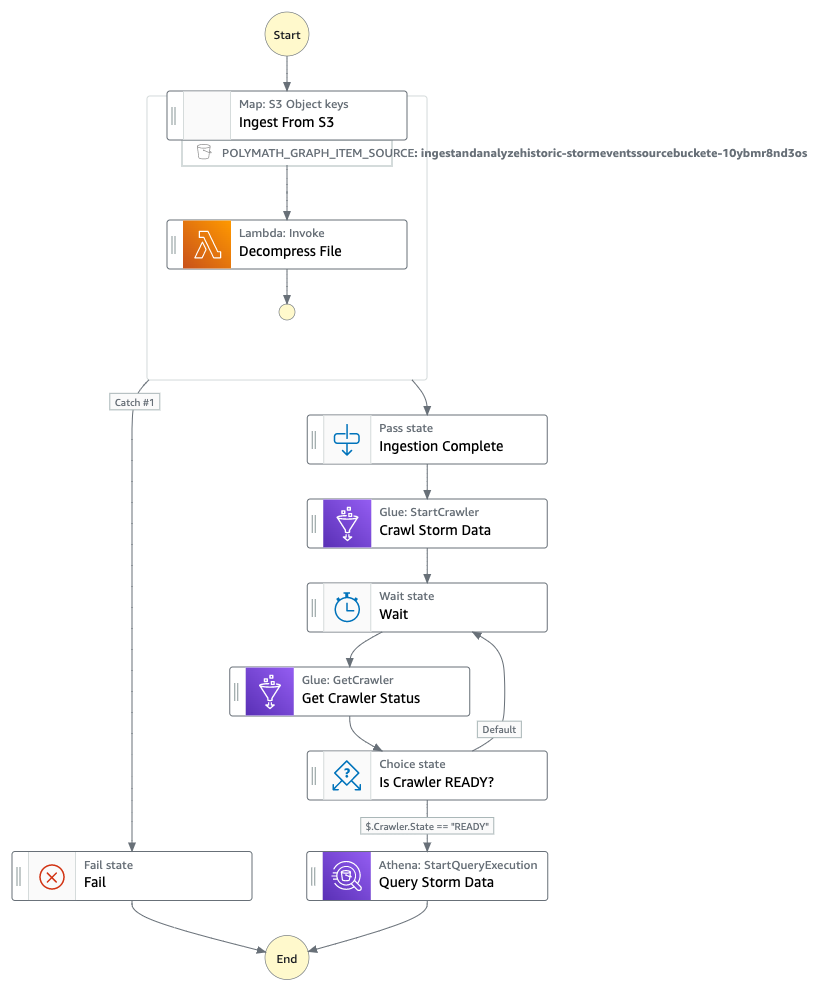
In this workflow we will use the distributed map feature of AWS Step functions by iterating over the raw compressed files (.gz) in the S3 bucket and decompressing them at scale. In the same orchestration process we will use AWS Glue Crawler to create/update the schema of the storm events. Once the crawl is process is complete, the step function will invoke the Athena query to retrieve the information from the AWS Glue data catalog tables
< Back to all workflows
Clone repo
git clone https://github.com/aws-samples/step-functions-workflows-collection/tree/main/ingest-and-analyze-historical-storm-events/cd step-functions-workflows-collection/ingest-and-analyze-historical-storm-events
Deploy
1. Bootstrap CDK, if needed: <code>cdk bootstrap aws://{your-aws-account-number}/{your-aws-region}</code>2. Deploy the stack: <code>cdk deploy</code>
Testing
See the GitHub repo for detailed testing instructions.
Cleanup
1. Delete the stack:
cdk destroy.Additional resources
Created by:

